6.3 Introducción al Análisis de Datos Masivos
En primer lugar se ha de considerar explorar los datos y realizar minería con ellos, y eso es posible hacerlo vía Sparklyr, como hemos visto, o para un análisis más visual, Rattle, que se presenta a continuación:
6.3.1 Rattle
Es un paquete para R, con interfaz gráfica desarrollada en GTK, que permite generar código R para minería de datos. Se instala según los pasos indicados a continuación:
install.packages("ggplot2")
install.packages("cairoDevice")
install.packages("RGtk2")
library("RGtk2")
install.packages("rattle")
library(rattle)
rattle()Un tutorial adecuado para introducirse en Rattle es éste
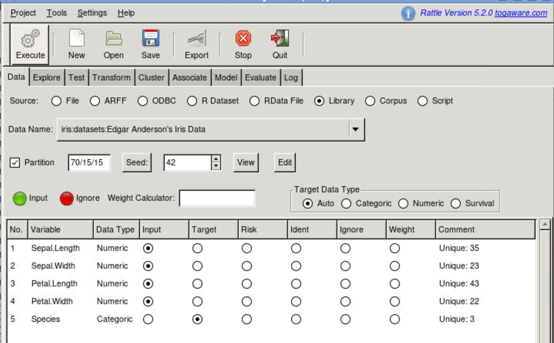
Con el tutorial se pueden ver las capacidades de rattle de explorar los datos, como se puede apreciar a continuación.
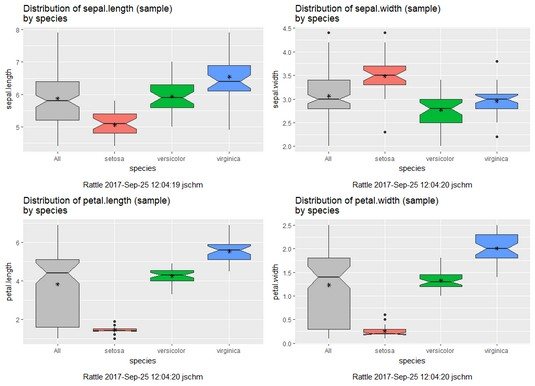
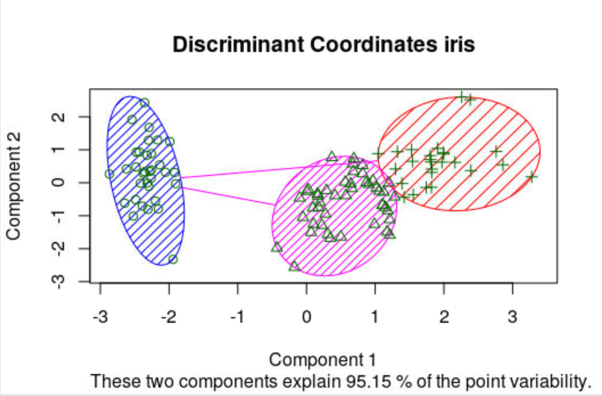
6.3.2 Combinando los distintos elementos
Vamos a seguir un tutorial de análisis de datos de vuelos, adaptándolo al entorno del CESGA.
En primer lugar, tras conectarnos por ssh al CESGA, y en el mismo directorio en que hemos hecho la conexión, nos descargamos los datos:
# Make download directory
mkdir flights
# Download flight data by year
for i in {1987..2008}
do
echo "$(date) $i Download"
fnam=$i.csv.bz2
wget -O flights/$fnam http://stat-computing.org/dataexpo/2009/$fnam
echo "$(date) $i Unzip"
bunzip2 flights/$fnam
done
# Download airline carrier data
wget -O airlines.csv http://www.transtats.bts.gov/Download_Lookup.asp?Lookup=L_UNIQUE_CARRIERS
# Download airports data
wget -O airports.csv https://raw.githubusercontent.com/jpatokal/openflights/master/data/airports.datComprobamos que los datos están correctos:
Y los copiamos al HDFS a través del comando fs de Hadoop:
# Copy flight data to HDFS
hadoop fs -put flights
# Copy airline data to HDFS
hadoop fs -mkdir airlines/
hadoop fs -put airlines.csv airlines
# Copy airport data to HDFS
hadoop fs -mkdir airports/
hadoop fs -put airports.csv airportsA continuación lanzamos la ejecución de ‘hive’:
Y creamos los metadatos que estructurarán la tabla de vuelos y cargamos los datos en la tabla Hive:
# Create metadata for flights
CREATE EXTERNAL TABLE IF NOT EXISTS flights230
(
year int,
month int,
dayofmonth int,
dayofweek int,
deptime int,
crsdeptime int,
arrtime int,
crsarrtime int,
uniquecarrier string,
flightnum int,
tailnum string,
actualelapsedtime int,
crselapsedtime int,
airtime string,
arrdelay int,
depdelay int,
origin string,
dest string,
distance int,
taxiin string,
taxiout string,
cancelled int,
cancellationcode string,
diverted int,
carrierdelay string,
weatherdelay string,
nasdelay string,
securitydelay string,
lateaircraftdelay string
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n'
TBLPROPERTIES("skip.header.line.count"="1");
# Load data into table
LOAD DATA INPATH 'flights' INTO TABLE flights230;Ídem para la tabla de aerolíneas, creamos los metadatos y cargamos los datos en la tabla HIVE:
# Create metadata for airlines
CREATE EXTERNAL TABLE IF NOT EXISTS airlines
(
Code string,
Description string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES
(
"separatorChar" = '\,',
"quoteChar" = '\"'
)
STORED AS TEXTFILE
tblproperties("skip.header.line.count"="1");
# Load data into table
LOAD DATA INPATH 'airlines' INTO TABLE airlines;Ídem para la tabla de aeropuertos, creamos los metadatos y cargamos los datos en la tabla HIVE:
# Create metadata for airports
CREATE EXTERNAL TABLE IF NOT EXISTS airports
(
id string,
name string,
city string,
country string,
faa string,
icao string,
lat double,
lon double,
alt int,
tz_offset double,
dst string,
tz_name string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES
(
"separatorChar" = '\,',
"quoteChar" = '\"'
)
STORED AS TEXTFILE;
# Load data into table
LOAD DATA INPATH 'airports' INTO TABLE airports;Nos conectamos a Spark (desde jupyter-lab o R): (alternativamente con ‘sc <- spark_connect(master = “local”)’ )
# Connect to Spark
library(sparklyr)
library(dplyr)
library(ggplot2)
sc <- spark_connect(master = "yarn-client", spark_home = Sys.getenv('SPARK_HOME'))
scSi tenemos problemas para conectar podemos gestionar con YARN los recursos
# Ver trabajos en YARN
yarn top
# Trabajos YARN en ejecución, en espera y aceptados
yarn application -list | grep RUNNING
yarn application -list | grep ACCEPTED
yarn application -list | grep SUBMITTED
# Cómo matar un trabajo YARN (si es de nuestro usuario). Indicar el ID de aplicación
yarn application -kill application_1575999528886_0161Crear tablas dplyr a tablas HIVE:
# Cache flights Hive table into Spark
#tbl_cache(sc, 'flights')
flights_tbl <- tbl(sc, 'flights230')
flights_tbl %>% print(width = Inf)# Cache airlines Hive table into Spark
#tbl_cache(sc, 'airlines')
airlines_tbl <- tbl(sc, 'airlines')
airlines_tbl %>% print(width = Inf)# Cache airports Hive table into Spark
#tbl_cache(sc, 'airports')
airports_tbl <- tbl(sc, 'airports')
airports_tbl %>% print(width = Inf)Ejemplos de análisis exploratorio de datos. Todos los vuelos por año:
system.time({
out <- flights_tbl %>%
group_by(year) %>%
count() %>%
arrange(year) %>%
collect()
})
out
out %>% ggplot(aes(x = year, y = n)) + geom_col()Vuelos con origen LAX (Los Angeles) por año:
system.time({
out <- flights_tbl %>%
filter(origin == "LAX") %>%
group_by(year) %>%
count() %>%
arrange(year) %>%
collect()
})
out
out %>% ggplot(aes(x = year, y = n)) +
geom_col() +
labs(title = "Number of flights from LAX")Y listado de países y número de aeropuertos:
Vamos a proceder a generar un conjunto de datos para calcular un modelo. Para ello buscaremos modelar como una regresión lineal la ganancia de un vuelo (gain) como (depdelay - arrdelay) basándose en la distancia, el retraso de la salida y la aerolínea usando datos del período 2003-2007:
# Filter records and create target variable 'gain'
system.time(
model_data <- flights_tbl %>%
filter(!is.na(arrdelay) & !is.na(depdelay) & !is.na(distance)) %>%
filter(depdelay > 15 & depdelay < 240) %>%
filter(arrdelay > -60 & arrdelay < 360) %>%
filter(year >= 2003 & year <= 2007) %>%
left_join(airlines_tbl, by = c("uniquecarrier" = "code")) %>%
mutate(gain = depdelay - arrdelay) %>%
select(year, month, arrdelay, depdelay, distance, uniquecarrier, description, gain)
)
model_data# Summarize data by carrier
model_data %>%
group_by(uniquecarrier) %>%
summarize(description = min(description), gain = mean(gain),
distance = mean(distance), depdelay = mean(depdelay)) %>%
select(description, gain, distance, depdelay) %>%
arrange(gain)Para entrenar la regresión lineal y predecir el tiempo ganado o perdido en un vuelo en función de la distancia, retraso en la salida y aerolínea procedemos de este modo:
# Partition the data into training and validation sets
model_partition <- model_data %>%
sdf_partition(train = 0.8, valid = 0.2, seed = 5555)
# Fit a linear model
system.time(
ml1 <- model_partition$train %>%
ml_linear_regression(gain ~ distance + depdelay + uniquecarrier)
)
# Summarize the linear model
summary(ml1)A continuación se compara la bondad del modelo con el subconjunto de validación
# Calculate average gains by predicted decile
system.time(
model_deciles <- lapply(model_partition, function(x) {
ml_predict(ml1, x) %>%
mutate(decile = ntile(desc(prediction), 10)) %>%
group_by(decile) %>%
summarize(gain = mean(gain)) %>%
select(decile, gain) %>%
collect()
})
)
model_deciles
# Create a summary dataset for plotting
deciles <- rbind(
data.frame(data = 'train', model_deciles$train),
data.frame(data = 'valid', model_deciles$valid),
make.row.names = FALSE
)
deciles
# Plot average gains by predicted decile
deciles %>%
ggplot(aes(factor(decile), gain, fill = data)) +
geom_bar(stat = 'identity', position = 'dodge') +
labs(title = 'Average gain by predicted decile', x = 'Decile', y = 'Minutes')Visualizar predicciones usando el año 2008 (no usado en el entrenamiento):
# Select data from an out of time sample
data_2008 <- flights_tbl %>%
filter(!is.na(arrdelay) & !is.na(depdelay) & !is.na(distance)) %>%
filter(depdelay > 15 & depdelay < 240) %>%
filter(arrdelay > -60 & arrdelay < 360) %>%
filter(year == 2008) %>%
left_join(airlines_tbl, by = c("uniquecarrier" = "code")) %>%
mutate(gain = depdelay - arrdelay) %>%
select(year, month, arrdelay, depdelay, distance, uniquecarrier, description, gain, origin, dest)
data_2008
# Summarize data by carrier
carrier <- ml_predict(ml1, data_2008) %>%
group_by(description) %>%
summarize(gain = mean(gain), prediction = mean(prediction), freq = n()) %>%
filter(freq > 10000) %>%
collect()
carrier
# Plot actual gains and predicted gains by airline carrier
ggplot(carrier, aes(gain, prediction)) +
geom_point(alpha = 0.75, color = 'red', shape = 3) +
geom_abline(intercept = 0, slope = 1, alpha = 0.15, color = 'blue') +
geom_text(aes(label = substr(description, 1, 20)), size = 3, alpha = 0.75, vjust = -1) +
labs(title='Average Gains Forecast', x = 'Actual', y = 'Predicted')Al terminar cualquier ejercicio con sparklyr desconectamos de Spark: