D.2 Métodos de aprendizaje estadístico
Aprendizaje no supervisado: Métodos exploratorios (sin variable respuesta). El objetivo principal es entender las relaciones y estructura de los datos.
Análisis descriptivo
Métodos de reducción de la dimensión (análisis de componentes principales, análisis factorial,…)
Clúster
Detección de datos atípicos
Aprendizaje supervisado: Métodos predictivos (con variable respuesta). El objetivo principal es la construcción de modelos, principalmente para predecir. Dependiendo del tipo de variable respuesta:
Clasificación: cualitativa
Regresión: numérica
D.2.1 Métodos (de aprendizaje supervisado):
Métodos de Clasificación:
Análisis discriminante (lineal, cuadrático), Regresión logística, multinomial, …
Árboles de decisión, bagging, random forest, boosting
Support vector machines (SVM)
Métodos de regresión:
Modelos lineales:
Regresión lineal:
lm(),lme(),biglm, …Regresión lineal robusta:
MASS::rlm(), …Métodos de regularización (Ridge regression, Lasso):
glmnet, …
Modelos lineales generalizados:
glm(),bigglm, ..Modelos paramétricos no lineales:
nls(),nlme, …Regresión local (métodos de suavizado):
loess(),KernSmooth,sm,np, …Modelos aditivos generalizados (GAM):
mgcv,gam, …Arboles de decisión, Random Forest, Boosting:
rpart,randomForest,xgboost, …Redes neuronales:
nnet, …
Paquetes con entornos gráficos (datos en memoria):
R-Commander + FactoMineR:
Rcmdr,RcmdrPlugin.FactoMineRRattle:
rattle
D.2.2 Construcción y evaluación de los modelos
El procedimiento habitual es particionar la base de datos en 2 (o incluso en 3) conjuntos:
Conjunto de datos de aprendizaje para construir los modelos
Conjunto de datos de (test) validación para (afinar) evaluar el rendimiento de los modelos
Alternativas: validación cruzada, bagging (bootstrap de las observaciones)
En el caso de grandes conjuntos de datos las aproximaciones más empleadas son:
Submuestreo: la idea es que a partir de un cierto número de observaciones el incremento en la precisión es relativamente pequeño3.
Computación paralela/distribuida:
Resumir (paralela/distribuida) -> Combinar -> Modelar
Modelar (paralela/distribuida) -> Combinar
Se puede implementar mediante un sistema MapReduce (Hadoop): los datos se procesan de forma distribuida mediante Mappers y los resultados se combinan mediante Reducers.
D.2.3 Matriz de confusión
Para estudiar la eficiencia de un método de clasificación supervisada se evalúa el modelo en el conjunto de datos de validación y se genera una tabla de contingencia con las predicciones (columnas) frente a los valores reales (filas).
| Observado\Predicción | Positivo | Negativo |
|---|---|---|
| Verdadero | Verdadero positivo | Falso negativo |
| Falso | Falso positivo | Verdadero negativo |
A partir de esta tabla se pueden estimar las tasas de falsos y verdaderos negativos y positivos (caso de dos categorías).
D.2.4 Predicciones frente a observado
Para estudiar la eficiencia de un método de regresión se evalúa el modelo en el conjunto de datos de validación y se comparan las predicciones frente a los valores reales
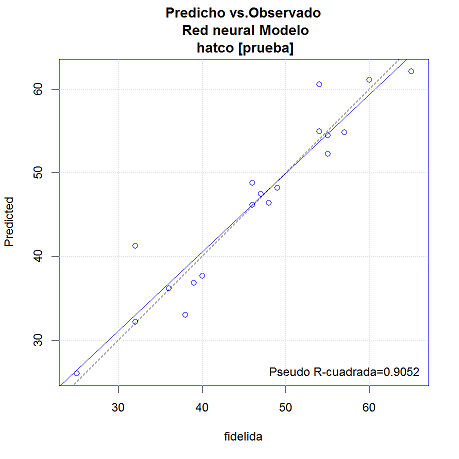
Las predicciones deberían estar próximas a los valores reales \(y=x\), en azul.
El pseudo R-cuadrado (el cuadrado de la correlación entre las predicciones y los valores observados, que se corresponde con la línea discontinua) debería ser próximo a 1.
El error de estimación suele ser de orden \(n^{-1/2}\) o superior, incrementar cuatro veces el número de datos disminuye el error de
estimación a la mitad o menos↩︎