2.2 Manipulación de datos
Una vez cargada una (o varias) bases de datos hay una series de operaciones que serán de interés para el tratamiento de datos:
- Operaciones con variables:
- crear
- recodificar (e.g. categorizar)
- …
- Operaciones con casos:
- ordenar
- filtrar
- …
- Operaciones con tablas de datos:
- unir
- combinar
- consultar
- …
A continuación se tratan algunas operaciones básicas.
2.2.1 Operaciones con variables
2.2.1.1 Creación (y eliminación) de variables
Consideremos de nuevo la base de datos cars incluida en el paquete datasets:
## speed dist
## 1 4 2
## 2 4 10
## 3 7 4
## 4 7 22
## 5 8 16
## 6 9 10Utilizando el comando help(cars) se obtiene que cars es un data.frame con 50
observaciones y dos variables:
speed: Velocidad (en millas por hora)dist: tiempo hasta detenerse (en pies)
Recordemos que, para acceder a la variable speed se puede
hacer directamente con su nombre o bien utilizando notación
“matricial” (se seleccionan las 6 primeras observaciones por comodidad).
## [1] 4 4 7 7 8 9 10 10 10 11 11 12 12 12 12 13 13 13
## [19] 13 14 14 14 14 15 15 15 16 16 17 17 17 18 18 18 18 19
## [37] 19 19 20 20 20 20 20 22 23 24 24 24 24 25Supongamos ahora que queremos transformar la variable original speed
(millas por hora) en una nueva variable velocidad (kilómetros por
hora) y añadir esta nueva variable al data.frame cars.
La transformación que permite pasar millas a kilómetros es
kilómetros=millas/0.62137 que en R se hace directamente con:
Finalmente, incluimos la nueva variable que llamaremos
velocidad en cars:
## speed dist velocidad
## 1 4 2 6.437388
## 2 4 10 6.437388
## 3 7 4 11.265430
## 4 7 22 11.265430
## 5 8 16 12.874777
## 6 9 10 14.484124También transformaremos la variable dist (en pies) en una nueva
variable distancia (en metros), por lo que la transformación deseada es
metros=pies/3.2808:
## speed dist velocidad distancia
## 1 4 2 6.437388 0.6096074
## 2 4 10 6.437388 3.0480371
## 3 7 4 11.265430 1.2192148
## 4 7 22 11.265430 6.7056815
## 5 8 16 12.874777 4.8768593
## 6 9 10 14.484124 3.0480371Ahora, eliminaremos las variables originales speed y
dist, y guardaremos el data.frame resultante con el nombre coches.
En primer lugar, veamos varias formas de acceder a las variables de
interés:
Utilizando alguna de las opciones anteriores se obtiene el data.frame
deseado:
## 'data.frame': 50 obs. of 2 variables:
## $ velocidad: num 6.44 6.44 11.27 11.27 12.87 ...
## $ distancia: num 0.61 3.05 1.22 6.71 4.88 ...Finalmente, los datos anteriores podrían ser guardados en un fichero exportable a Excel con el siguiente comando:
2.2.1.2 Recodificación de variables
Con el comando cut() podemos crear variables categóricas a partir de variables numéricas.
El parámetro breaks permite especificar los intervalos para la discretización, puede ser un vector con los extremos de los intervalos o un entero con el número de intervalos.
Por ejemplo, para categorizar la variable cars$speed en tres intervalos equidistantes podemos emplear1:
## fspeed
## Baja Media Alta
## 11 24 15Para categorizar esta variable en tres niveles con aproximadamente el mismo número de observaciones podríamos combinar esta función con quantile():
breaks <- quantile(cars$speed, probs = 0:3/3)
etiquetas3 <- c("Baja", "Media", "Alta")
fspeed <- cut(cars$speed, breaks, labels = etiquetas3)
table(fspeed)## fspeed
## Baja Media Alta
## 17 16 15Para otro tipo de recodificaciones podríamos emplear la función ifelse() vectorial:
fspeed <- ifelse(cars$speed < 15, "Baja", "Alta")
etiquetas2 <- c("Baja", "Alta")
fspeed <- factor(fspeed, levels = etiquetas2)
table(fspeed)## fspeed
## Baja Alta
## 23 27Alternativamente, en el caso de dos niveles podríamos emplear directamente la función factor():
## fspeed
## Baja Alta
## 23 27En el caso de múltiples niveles, se podría emplear ifelse() anidados:
fspeed <- ifelse(cars$speed < 10, "Baja",
ifelse(cars$speed < 20, "Media", "Alta"))
fspeed <- factor(fspeed, levels = etiquetas3)
table(fspeed)## fspeed
## Baja Media Alta
## 6 32 12Otra alternativa, sería emplear la función recode() del paquete car.
library(car)
fspeed <- recode(cars$speed, "0:10 = 'Baja';
10:20 = 'Media';
else='Alta'
")
fspeed <- factor(fspeed, levels = c("Baja", "Media", "Alta"))NOTA: Para acceder directamente a las variables de un data.frame podríamos emplear la función attach() para añadirlo a la ruta de búsqueda y detach() al finalizar.
Sin embargo esta forma de proceder puede causar numerosos inconvenientes, especialmente al modificar la base de datos, por lo que la recomendación sería emplear with().
Por ejemplo, podríamos calcular el factor anterior empleando:
fspeed <- with(cars, ifelse(speed < 10, "Baja",
ifelse(speed < 20, "Media", "Alta")))
fspeed <- factor(fspeed, levels = c("Baja", "Media", "Alta"))
table(fspeed)## fspeed
## Baja Media Alta
## 6 32 122.2.2 Operaciones con casos
2.2.2.1 Ordenación
Continuemos con el data.frame cars.
Se puede comprobar que los datos disponibles están ordenados por
los valores de speed. A continuación haremos la ordenación utilizando
los valores de dist. Para ello, utilizaremos el conocido como vector de
índices de ordenación.
Este vector establece el orden en que tienen que ser elegidos los
elementos para obtener la ordenación deseada.
Veamos primero un ejemplo sencillo:
## [1] 3 1 4 2 5## [1] 1.2 2.5 3.1 4.3 5.0En el caso de vectores, el procedimiento anterior se podría hacer directamente con:
Sin embargo, para ordenar tablas de datos será necesario la utilización del
vector de índices de ordenación. A continuación, se muestan los datos de cars ordenados por dist:
ii <- order(cars$dist) # Vector de índices de ordenación
cars2 <- cars[ii, ] # Datos ordenados por dist
head(cars2)## speed dist velocidad distancia
## 1 4 2 6.437388 0.6096074
## 3 7 4 11.265430 1.2192148
## 2 4 10 6.437388 3.0480371
## 6 9 10 14.484124 3.0480371
## 12 12 14 19.312165 4.2672519
## 5 8 16 12.874777 4.87685932.2.2.2 Filtrado
El filtrado de datos consiste en elegir una submuestra que cumpla determinadas condiciones. Para ello, se puede utilizar la función subset(x, subset, select, drop = FALSE, ...) , que además permite seleccionar variables con el argumento select.
A continuación se muestran un par de ejemplos:
## speed dist velocidad distancia
## 47 24 92 38.62433 28.04194
## 48 24 93 38.62433 28.34674
## 49 24 120 38.62433 36.57644## speed dist velocidad distancia
## 19 13 46 20.92151 14.02097
## 22 14 60 22.53086 18.28822
## 23 14 80 22.53086 24.38430También se pueden hacer el filtrado empleando directamente los correspondientes vectores de índices:
## speed dist velocidad distancia
## 47 24 92 38.62433 28.04194
## 48 24 93 38.62433 28.34674
## 49 24 120 38.62433 36.57644## speed dist velocidad distancia
## 19 13 46 20.92151 14.02097
## 22 14 60 22.53086 18.28822
## 23 14 80 22.53086 24.38430En este caso, puede ser de utilidad la función which():
## int [1:3] 19 22 23## speed dist velocidad distancia
## 19 13 46 20.92151 14.02097
## 22 14 60 22.53086 18.28822
## 23 14 80 22.53086 24.38430## 'data.frame': 47 obs. of 4 variables:
## $ speed : num 4 4 7 7 8 9 10 10 10 11 ...
## $ dist : num 2 10 4 22 16 10 18 26 34 17 ...
## $ velocidad: num 6.44 6.44 11.27 11.27 12.87 ...
## $ distancia: num 0.61 3.05 1.22 6.71 4.88 ...## 'data.frame': 47 obs. of 4 variables:
## $ speed : num 4 4 7 7 8 9 10 10 10 11 ...
## $ dist : num 2 10 4 22 16 10 18 26 34 17 ...
## $ velocidad: num 6.44 6.44 11.27 11.27 12.87 ...
## $ distancia: num 0.61 3.05 1.22 6.71 4.88 ...Si se realiza una selección de variables como en:
## [1] 13 14 14es posible que se quiera mantener la estructura original de los datos, para ello, bastaría con:
## speed
## 19 13
## 22 14
## 23 14A veces puede ser necesario dividir (particionar) el conjunto de datos, uno para cada nivel de un grupo (factor), para ello se puede usar la función split():
## speed2
## slow fast
## 43 7## [1] "list"## slow fast
## "data.frame" "data.frame"## slow fast
## [1,] 43 7
## [2,] 4 4## speed dist velocidad distancia
## 44 22 66 35.40564 20.11704
## 45 23 54 37.01498 16.45940
## 46 24 70 38.62433 21.33626
## 47 24 92 38.62433 28.04194
## 48 24 93 38.62433 28.34674
## 49 24 120 38.62433 36.57644
## 50 25 85 40.23368 25.90832De forma inversa, podríamos recuperar el data.frame original con:
2.2.3 Datos faltantes
La problemática originada por los datos faltantes (missing data) en cualquier conjunto de datos subyace cuando se desea realizar un análisis estadístico, para más información en R, se puede consultar CRAN Task View: Missing Data
Vamos a ver un ejemplo, empleando el conjunto de datos airquality que contiene datos falntantes en sus dos primeras variables:
## Ozone Solar.R Wind
## Min. : 1.00 Min. : 7.0 Min. : 1.700
## 1st Qu.: 18.00 1st Qu.:115.8 1st Qu.: 7.400
## Median : 31.50 Median :205.0 Median : 9.700
## Mean : 42.13 Mean :185.9 Mean : 9.958
## 3rd Qu.: 63.25 3rd Qu.:258.8 3rd Qu.:11.500
## Max. :168.00 Max. :334.0 Max. :20.700
## NA's :37 NA's :7## [1] 153## Ozone Solar.R Wind
## 37 7 0A continuación se muestra la distribución de los datos perdidos en el data.frame (a lo largo del tiempo, por mes):
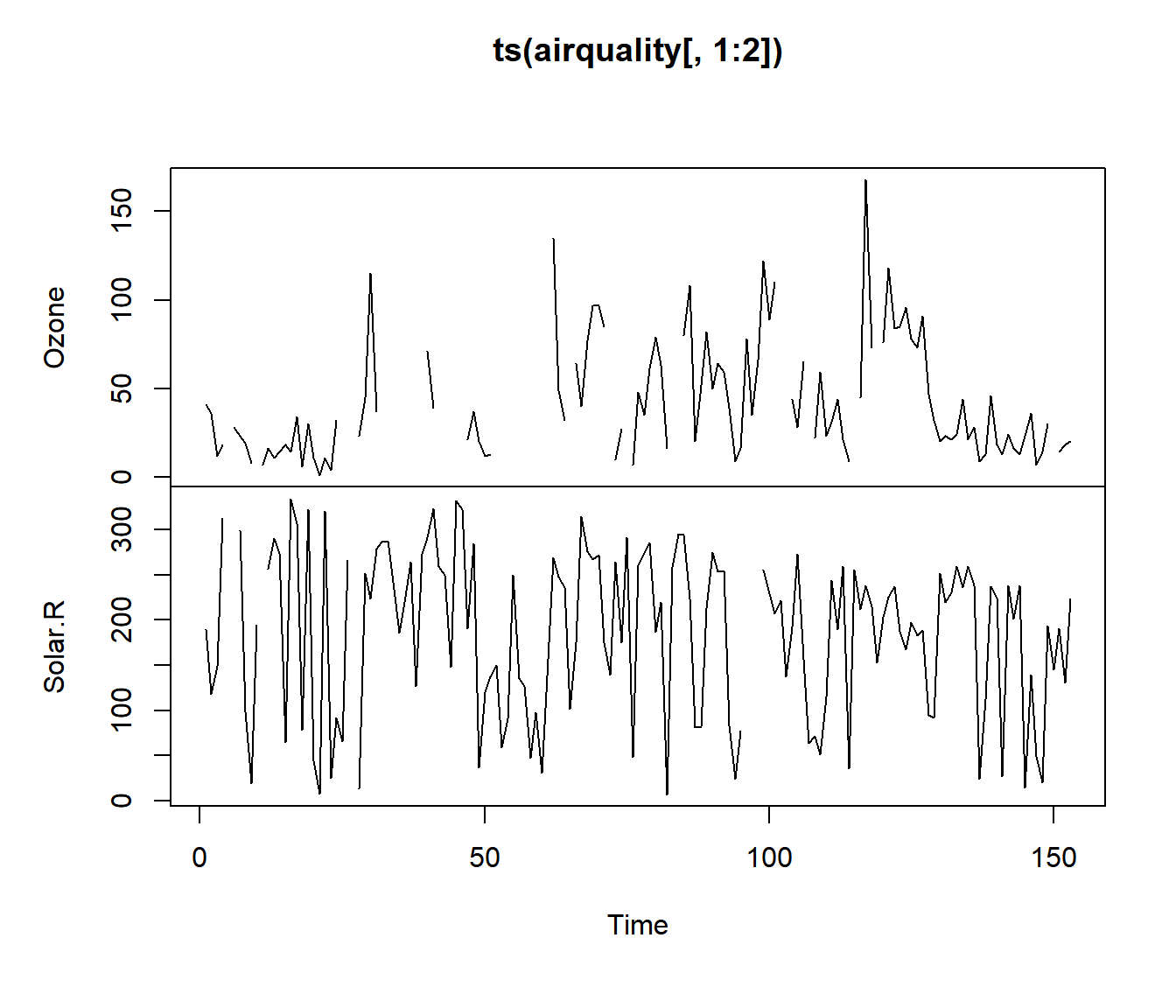
¿Existe un patrón no aleatorio en los datos faltantes del ozono? Esta pregunta puede ser abordada parcialmente utilizando el test de Little (Little 1988), disponible en la función mcar_test() del paquete naniar. Este test permite evaluar si los datos faltantes son generados por un mecanismo completamente aleatorio (MCAR). Si la hipótesis de MCAR es rechazada, esto sugiere que los datos faltantes podrían estar siguiendo un mecanismo MAR (missing at random) o MNAR (non missing at random).
Sin embargo, en muchos estudios, se omite el paso anterior y se procede directamente con alguno de los siguientes métodos:
- Análisis de casos completos (complete cases)
- Análisis de casos disponibles (borrado por parejas pairwise cases)
- Imputación de datos faltantes (por la media, mediana, último valor observado, vecino más cercano, valores predichos usando los datos observados….)
Siguiendo con el ejemplo, ante la presencia de datos faltantes, en R inicialmente no podemos conocer cómo se relacionan las tres primeras variables:”
## Ozone Solar.R Wind
## Ozone 1 NA NA
## Solar.R NA 1 NA
## Wind NA NA 1y requiere indicar cómo tratar los datos perdidos. Por ejemplo, una opción sería realizar un análisis sólo de los casos completos, eliminando todas las observaciones (filas) con algún dato faltante de nuestro conjunto de datos:
## [1] 111## Ozone Solar.R Wind
## Ozone 1.0000000 0.3483417 -0.6124966
## Solar.R 0.3483417 1.0000000 -0.1271835
## Wind -0.6124966 -0.1271835 1.0000000# otra forma de hacerlo sería:
# nrow(datos[complete.cases(datos),])
# cor(datos[,1:3], use ="complete.obs") También, se podría usar toda la información disponible. El tamaño muestral \(n\) sería variable en función de los NA’s de cada par de variables:
## Ozone Solar.R Wind
## Ozone 1.0000000 0.34834169 -0.60154653
## Solar.R 0.3483417 1.00000000 -0.05679167
## Wind -0.6015465 -0.05679167 1.00000000Por ejmmplo, ahora la correlación usa los \(146\) pares de observaciones disponibles para (Solar.R,Wind), en lugar de \(111\) del primer caso.
Por último, también se podría realizar una imputación (Van Buuren 2018). A modo de ejemplo, en el siguiente código, se utiliza la media:
datosI <- datos
datosI$Ozone[is.na(datos$Ozone)] <- mean(datos$Ozone, na.rm = T)
datosI$Solar.R[is.na(datos$Solar.R)] <- mean(datosI$Solar.R, na.rm = T)
cor(datosI[,1:3])## Ozone Solar.R Wind
## Ozone 1.0000000 0.30296951 -0.53093584
## Solar.R 0.3029695 1.00000000 -0.05524488
## Wind -0.5309358 -0.05524488 1.00000000Notar que para el caso del ozono, se han sustituido los 37 NA’s (24% de las observaciones) por un único valor (de ahí que ahora la varianza sea menor a la observada inicialmente, algo que en principio, no sería deseable).
## [1] 1088.201## [1] 823.3096Los datos faltantes son una realidad común en muchos estudios, aunque nadie los desea. Para tratarlos correctamente, es esencial comprender cómo se obtuvieron los datos observados y por qué algunos datos no fueron registrados antes de iniciar cualquier otro análisis. No abordar adecuadamente los datos faltantes puede tener un efecto perjudicial en nuestro estudio, ya que las conclusiones obtenidas podrían ser no representativas o contener sesgos.
2.2.4 Funciones apply
2.2.4.1 La función apply
Una forma de evitar la utilización de bucles es utilizando la sentencia apply que permite evaluar una misma función en todas las filas, columnas, etc. de un array de forma simultánea.
La sintaxis de esta función es:
X: matriz (o array).MARGIN: un vector indicando las dimensiones donde se aplicará la función. 1 indica filas, 2 indica columnas, yc(1,2)indica filas y columnas.FUN: función que será aplicada....: argumentos opcionales que serán usados porFUN.
Veamos la utilización de la función apply con un ejemplo:
## [,1] [,2] [,3]
## [1,] 1 4 7
## [2,] 2 5 8
## [3,] 3 6 9## [1] 12 15 18## [1] 6 15 24## [1] 1 4 7## [,1] [,2] [,3]
## [1,] 1 4 7
## [2,] 3 6 9Alternativamente, se puede utilizar opciones más eficientes: colSums(), rowSums(), colMeans() y rowMeans(), como se muestra en el siguiente código de ejemplo:
x <- matrix(1:1e8, ncol = 10, byrow = FALSE)
t1 <- proc.time()
out<-apply(x, 2, mean)
proc.time() - t1## user system elapsed
## 1.223 0.503 1.728## user system elapsed
## 0.179 0.000 0.1792.2.4.2 Variantes de la función apply
- La función
lapply(X, FUN, ...)aplica la funciónFUNa cada elemento de una lista en R y devuelve una lista como resultado (sin necesidad de especificar el argumento MARGIN). Notar que todas las estructuras de datos en R pueden convertirse en listas, por lo quelapply()puede utilizarse en más casos queapply().
## List of 4
## $ speed : num 15
## $ dist : num 36
## $ velocidad: num 24.1
## $ distancia: num 11- La función
sapply(X, FUN, ..., simplify = TRUE, USE.NAMES = TRUE)permite iterar sobre una lista o vector (alternativa más eficiente a unfor):
# matriz con las medias, medianas y desv. de las variables
res <- sapply(cars,
function(x) c(mean = mean(x),
median = median(x),
sd = sd(x)))
# str(res)
res## speed dist velocidad distancia
## mean 15.400000 42.98000 24.783945 13.100463
## median 15.000000 36.00000 24.140206 10.972933
## sd 5.287644 25.76938 8.509655 7.854602## [1] 5.50000 5.50000 3.02765## speed dist velocidad distancia
## [1,] 15.400000 42.98000 24.783945 13.100463
## [2,] 15.000000 36.00000 24.140206 10.972933
## [3,] 5.287644 25.76938 8.509655 7.854602## mean median sd
## 5.50000 5.50000 3.02765- La función
tapply()es similar a la funciónapply()y permite aplicar una función a los datos desagregados, utilizando como criterio los distintos niveles de una variable factor. Es decir, facilita la creación de tablars resumen por grupos. La sintaxis de esta función es como sigue:
X: matriz (o array).INDEX: factor indicando los grupos (niveles).FUN: función que será aplicada....: argumentos opcionales .
Consideremos, por ejemplo, el data.frame ChickWeight con datos de un
experimento relacionado con la repercusión de varias dietas en el peso
de pollos.
## weight Time Chick Diet
## 1 42 0 1 1
## 2 51 2 1 1
## 3 59 4 1 1
## 4 64 6 1 1
## 5 76 8 1 1
## 6 93 10 1 1peso <- ChickWeight$weight
dieta <- ChickWeight$Diet
levels(dieta) <- c("Dieta 1", "Dieta 2", "Dieta 3", "Dieta 4")
tapply(peso, dieta, mean) # Peso medio por dieta## Dieta 1 Dieta 2 Dieta 3 Dieta 4
## 102.6455 122.6167 142.9500 135.2627## $`Dieta 1`
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 35.00 57.75 88.00 102.65 136.50 305.00
##
## $`Dieta 2`
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 39.0 65.5 104.5 122.6 163.0 331.0
##
## $`Dieta 3`
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 39.0 67.5 125.5 142.9 198.8 373.0
##
## $`Dieta 4`
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 39.00 71.25 129.50 135.26 184.75 322.00Alternativamente, se podría emplear la función aggregate() que tiene las ventajas de admitir fórmulas y disponer de un método para series de tiempo.
## dieta x
## 1 Dieta 1 102.6455
## 2 Dieta 2 122.6167
## 3 Dieta 3 142.9500
## 4 Dieta 4 135.2627## dieta peso.Min. peso.1st Qu. peso.Median peso.Mean
## 1 Dieta 1 35.0000 57.7500 88.0000 102.6455
## 2 Dieta 2 39.0000 65.5000 104.5000 122.6167
## 3 Dieta 3 39.0000 67.5000 125.5000 142.9500
## 4 Dieta 4 39.0000 71.2500 129.5000 135.2627
## peso.3rd Qu. peso.Max.
## 1 136.5000 305.0000
## 2 163.0000 331.0000
## 3 198.7500 373.0000
## 4 184.7500 322.00002.2.5 Generación de tablas
Hay muchos paquetes de R que se pueden utilizar para generar tablas en informes RMarkdown o en aplicaciones shiny.
Entre las herramientas disponibles podríamos destacar la función kable() del paquete knitr para generar tablas básicas, y la función datatable() del paquete DT para generar tablas dinámicas.
Otros paquetes son:
kableExtra, flextable, reactable, reactablefmtr,
formattable, gt y tinytable.
2.2.5.1 Tablas con kable()
A continuación, se muestra un ejemplo, de tabla resumen, con las medias, medianas y desviación típica de las variables:
res <- sapply(cars,
function(x) c(mean = mean(x),
median = median(x),
sd = sd(x)))
knitr::kable(t(res), digits = 1,
col.names = c("Media", "Mediana", "Desv. típica"))| Media | Mediana | Desv. típica | |
|---|---|---|---|
| speed | 15.4 | 15.0 | 5.3 |
| dist | 43.0 | 36.0 | 25.8 |
| velocidad | 24.8 | 24.1 | 8.5 |
| distancia | 13.1 | 11.0 | 7.9 |
Y en este segundo ejemplo, se muestra el resumen de un modelo de regresión lineal simple (distancia de frenado en función de la velocidad del vehículo):
modelo <- lm(dist ~ speed, data = cars)
coefs <- coef(summary(modelo))
knitr::kable(coefs, escape = FALSE, digits = 5)| Estimate | Std. Error | t value | Pr(>|t|) | |
|---|---|---|---|---|
| (Intercept) | -17.57909 | 6.75844 | -2.60106 | 0.01232 |
| speed | 3.93241 | 0.41551 | 9.46399 | 0.00000 |
2.2.6 Operaciones con tablas de datos
Unir tablas:
rbind(): combina vectores, matrices, arrays o data.frames por filas.cbind(): Idem por columnas.merge(): Fusiona dos data.frame por columnas o nombres de fila comunes. También permite otras operaciones de unión (join) de bases de datos, algunas de ellas se verán con más detalle en el Capítulo 4.
Combinar tablas:
match(x, table)devuelve un vector (de la misma longitud quex) con las (primeras) posiciones de coincidencia dexentable(oNA, por defecto, si no hay coincidencia).Para realizar consultas combinando tablas puede ser más cómodo el operador
%in%(?'%in%').pmatch(x, table, ...): similar al anterior pero con coincidencias parciales de cadenas de texto.
References
Aunque si el objetivo es obtener las frecuencias de cada intervalo puede ser más eficiente emplear
hist()conplot = FALSE.↩︎